Guild Queues
Redis-based distributed job queue library for Guild.xyz's backend infrastructure.

Installation
npm install @guildxyz/queuesExample usage
import { AccessFlow } from "@guildxyz/queues";
// create the flow instance
const accessFlow = new AccessFlow({
redisClientOptions: { url: config.redisHost },
logger,
});
// set up the worker
accessFlow.createChildWorker("manage-reward:discord", async (job) => {
const success = await handleAccessEvent(job);
return { success };
});
// start
accessFlow.startAll();How it works
Why redis?
- most message/job queue implementations don't support exactly-once processing
- we don't want another "magic" technology like Prisma
- we are familiar with redis
- no vendor lock-in
- it's relatively easy to switch from
How can we implement job queues in redis?
- redis implements the list data structure and has commands (LMOVE or BLMOVE) to atomically remove the first/last element of a list and add this element to another list
- these commands are atomic, which guarantees that
- the element will only move to exactly one new list
- the element will be removed from the first array, so no inconsistency can happen
- BLMOVE is the blocking variant of LMOVE which means it will wait until an element is present in the first array, so we don't need to check it periodically
- basically we will have two queues (redis lists)
- the waiting queue, which contains the jobs waiting for execution
- the processing queue, which contains the jobs that are under execution
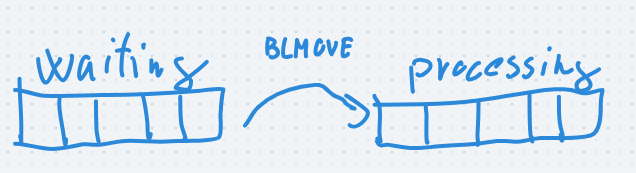
- conclusion: we can mark a job for execution and mark it exactly once and also avoid any kind of inconsistencies
Where to store the job's parameters / result?
- we can store the job's data serialized in the queues (lists) and deserialize them when we need to use their values, however this would caused several problems (we will see soon why)
- so we will store the job's data in another redis data structure, in a hash which is basically an object/map containing key-value pairs
- the hash will contain the params and later the result of the job, and the queues (lists) will only pass the job's ids among each other
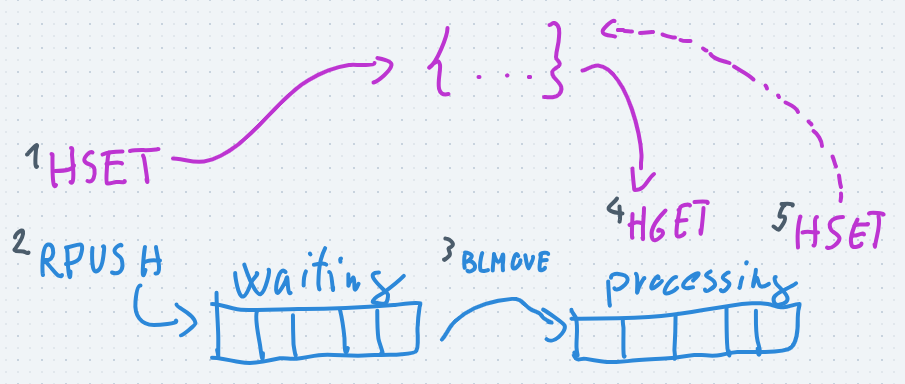
- so first we generate an ID for the job, save the job's data to a hash with the HSET command and put the job's ID to the waiting queue with the RPUSH command
- then when the job moves to the processing queue we can access the job's parameters buy fetching the hash's fields with the HGET command
- finally when the job is done we save the job's result to the hash with the HSET command
Example
Putting a job into the queue:
Put the job to a set
> HSET job:123 userId 62 guildId 1985
Thejob:123hash will be:{ userId: 62, guildId: 1985 }Put the job's id to the waiting queue
> RPUSH queue:waiting job:123The
queue:waitingwill be[job:123]
and thequeue:processingwill be[]
Processing a job:
Mark the job as processed
> BLMOVE queue:waiting queue:processing LEFT RIGHT
Thequeue:waitingwill be[]
and thequeue:processingwill be[job:123]Get the job's data
> HGET job:123 userId guildId
Will return:{ userId: 62, guildId: 1985 }now the job is executed with the parameters
Save the result
> HSET job:123 access true
Thejob:123hash will be:{ userId: 62, guildId: 1985 access: true }
all these commands have the amortized time complexity of
O(1)which basically means that the command will almost always complete in some constant time and won't get slower as the list grows, so we expect it to stay pretty fast even if the load is biggerconclusion: we can now store a job separately from the queues and retrieve/modify it's value
What happens when a job fails, how will this prevent us from losing ongoing jobs?
- When we move a job to the processing queue we know that it's under execution and expect a result soon. If there's no result, we assume that the job failed and retry it or mark it as failed.
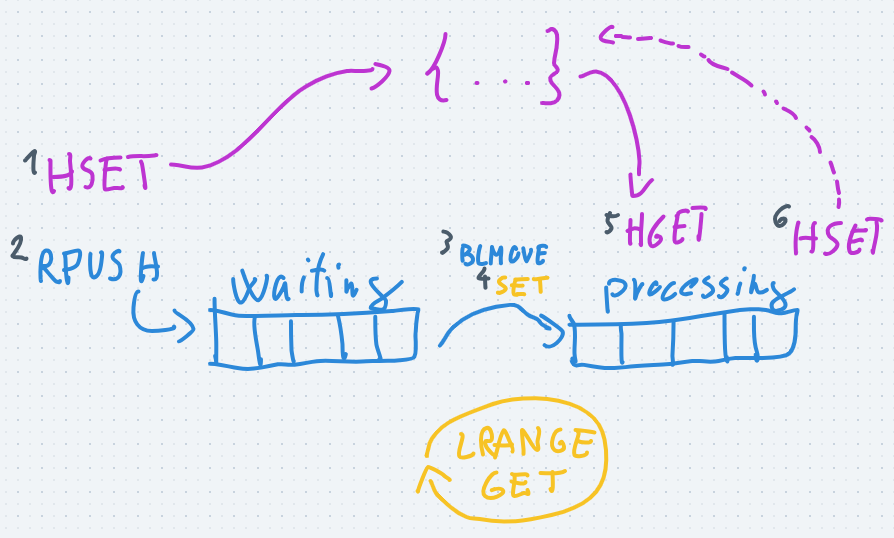
- So we need a timeout which indicates how much time we wait until we mark a job as failed. Redis natively supports key expiration so we will save a key (a "lock") whenever a job is being processed and periodically check if the job is done and whether there's a "lock" for it. If the job is not completed and there's no "lock" key for it, we assume that the job is failed and proceed.
- Saving the lock key is done by the SET command
> SET job:123:lock blabla EX 60
The value is not important yet, we just save the joblock key for 60 seconds. - For the periodical checking first we need to list the jobs that are processed at the moment:
> LRANGE queue:processing 0 -1
The LRANGE command will list a range of a list, and the 0 and -1 parameters mean the first and the last item, so all the items will be fetched.
Then we can easily check if a key is exists with the GET command
> GET job:123:lock
unfortunately we have to make a compromise here, the LRANGE command has the time complexity of O(N), which means it gets slower as the list grows
conclusion: no job is lost, if the execution fails, we will know about it
What happens when a job is done? How to execute a series of jobs?
- The motivation to create this lib was to put our access-check / job flow into queues instead of using stateless REST requests for communication or using some third-party library's queueing system (e.g. discord.js)
- So we want to create an abstraction for flows, sequences of jobs
- We can modify our current setup by putting a completed job's id to the next queue and basically creating a pipeline of jobs.
- One might think that moving a completed job from the current processing queue to the next waiting queue would easily solve this problem, but unfortunately that's not the case, because BLMOVE can only move the first/last element of a list, and if there're multiple jobs under execution we can't be sure that the completed job is the last in the list
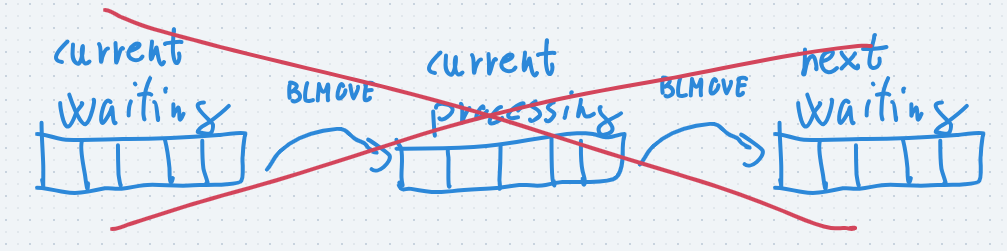
Example why this will not work:
- we create some jobs
waiting:[a, b, c, d, e] - we start executing the next job: a
waiting:[b, c, d, e]
processing:[a] - we start executing the next job: b
waiting:[c, d, e]
processing:[a, b] - we start executing the next job: c
waiting:[d, e]
processing:[a, b, c] - the execution of job b is finished, but we can't move it to another list with BLMOVE because it's in the middle of the list :(
- we create some jobs
So we need to move a specific element from the processing queue to another queue. Unfortunately redis does not have a native command to do this, so we will use two commands.
- LREM, to remove a specific element from the list
- RPUSH, to put the job to the next waiting queue
Because these are two separate commands and redis does not support ACID transactions we will have a tiny chance to cause inconsistency.
The most we can do is- we first RPUSH the job to the next queue, then remove it from the current one, so in the worst case it will be executed twice, but won't be lost
- use redis transactions which does not guarantee atomic execution but will make sure that no other command will be executed in the middle of the transaction, so we minimize the chance of making inconsistencies
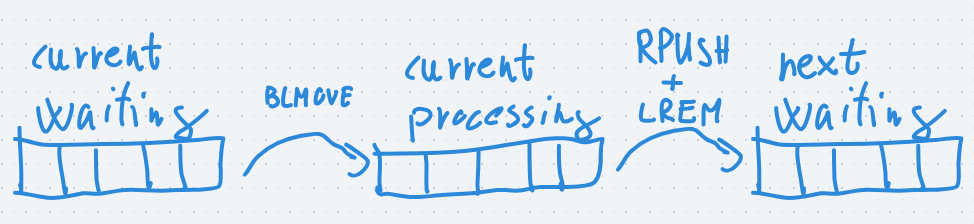
- unfortunately LREM also has the time complexity of O(n)
- conclusion: the completed jobs can be forwarded to the next queue, so we are able to create a pipeline of jobs which we will refer to as flows
Abstraction
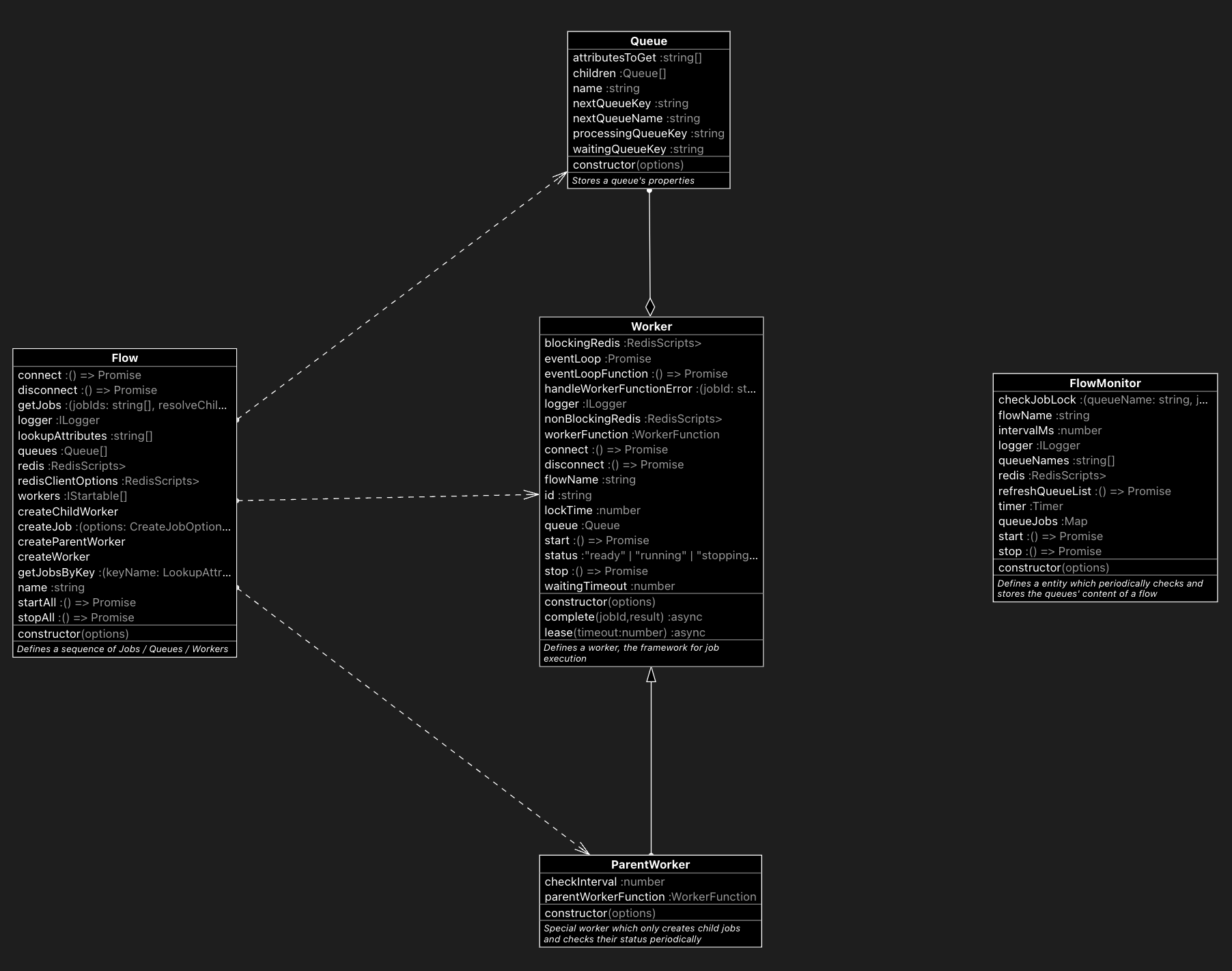
Queue
- we saw that all we need is a pair of redis lists to represent a basic job queue in redis
- we will have a Queue class which will represent this structure
- it will have a name (e.g. access-check)
- it will store the information about how it is stored in redis: the prefix (e.g.
queue:), the name of the waiting and processing queues (e.g.queue:access-check:waiting), etc. - and it will also store some basic information about what fields of the job's hash should be fetched as the job's parameters
- so basically a queue is a part of the flow / job pipeline
- for example the access-check (when the core asks the gate for the accesses of a given user and a role) will be 1 Queue
Flow
- A flow is a job pipeline, contains the information about
- the queues it consists of
- what job should be executed after one is finished (=what queue comes after another)
- a job's state (the information stored in redis hashes) is also defined by the flow, because the same hash will be used throughout the flow
- the Flow class is responsive for creating a new job and fetching it (for monitoring purposes)
Worker
- The jobs in the waiting queue are moved to the processing queue and executed then the result is saved.
- The entity that does the above is called the worker, it basically
- checks the waiting queue it belongs to
- marks a job for execution,
- fetches the job's data
- calls the provided WorkerFunction with the job's data (= execute the job)
- saves the job's result
- puts the job's ID to the next queue
- It stores
- the flow it belongs to
- the queue it belongs to
- the WorkerFunction which is the definition of the execution
Note: the redis hash where the job's data is stored will be called the state of the job or the state to make is shorter
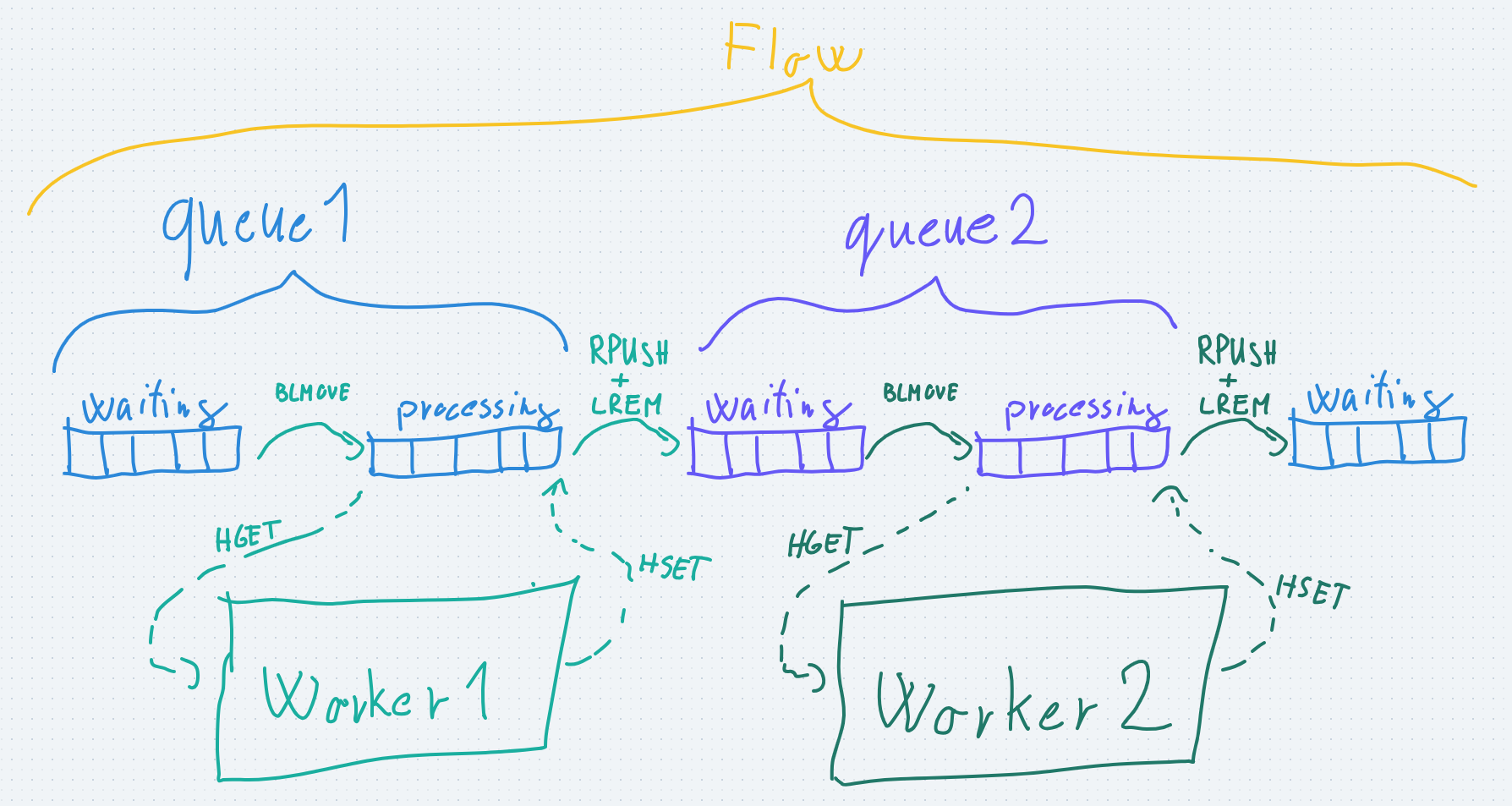
Example: the access/join flow https://whimsical.com/access-queue-TGADUnGjaVLEV139AoPxdZ@VsSo8s35Wy8ndXd5AHDbf5
UML class diagram
Everybody gangsta until the flow splits into multiple sub-queues
- Unfortunately the join flow has a part where it gets more complicated than just having one queue after another. After the access-check and the membership updates are done we need to give platform accesses to the user in different platforms. Here the flow basically splits into multiple sub-queues, which we will call child-queues.
WIP
Handling Rate limits
WIP https://whimsical.com/access-queue-TGADUnGjaVLEV139AoPxdZ@VsSo8s35WxWyF2SRXAgTFy
Advanced job scheduling
WIP
Job priorities
WIP
Miscellaneous
Can we avoid LREM and other O(N)s?
https://whimsical.com/access-queue-TGADUnGjaVLEV139AoPxdZ@VsSo8s35WxiSx1ZMS2Urdd