scaphold-sync v1.0.0
Scaphold Sync System (scaphold-sync)
![]()
Node.js sync tools to deal with scaphold.io databases.
Installation
Get it with NPM!
$ npm install scaphold-sync -gThen you will get a scaphold-sync command that has quite a few options
$ scaphold-sync --help
scaphold-sync <command> <options>
Commands:
compare Compare a scaphold database to the local schema folder.
deploy Update a scaphold database to match the local schema folder.
down Download the scaphold database to a local schema folder.
endpoint Get the endpoint user by serverless.
exec Execute a set of commands on scaphold that are piped in as JSON.
stream Like exec but processes input as JSON stream rather than JSON
Object, potentially faster, potentially more dangerous.
Options:
--appName, --name, -n Scaphold Application Name [string] [required]
--region, -r Scaphold Region, taken from package.json if
available. else it will assume us-west-2.
[string]
--concurrency, --cops, -o Maximum concurrent operations run against
scaphold. [number] [default: 5]
--cwd, -c Folder with a package.json that contains
scaphold access credentials.
[string] [default: "."]
--schemaFolder, --schema, -s Folder to store the scaphold schema data.
[string] [default: "./schema"]
--appId, --id, -i Scaphold application ID, taken from package.json
if available [string]
--help Show help [boolean]
--schemaFolder, set to "/Users/warrantee/Documents/scaphold-sync/schema", does not exist.Working with scaphold schemas
scaphold-sync has its own, custom, implementation to download and store
the scaphold database schema as files. It also holds an implementation to
compare the information in the files with a scaphold database and
automatically change the online database.
Scaphold connection setup
scaphold-sync needs the specification of three options in order to connect
to a database:
--regionis the region that the databases are running on at Scaphold.
--appNameis thealiasof the Scaphold database.
--appIdis the application ID that Scaphold uses internally to identify the database. Unfortunately this is not easy to find. You need to look in the chrome debugger:- Open the Scaphold Backend.
- Open the Chrome Developer tools
- Select the Network Panel
- Refresh the page
Look for the request to
/managementwith agetAppquery. Theidis the--appId.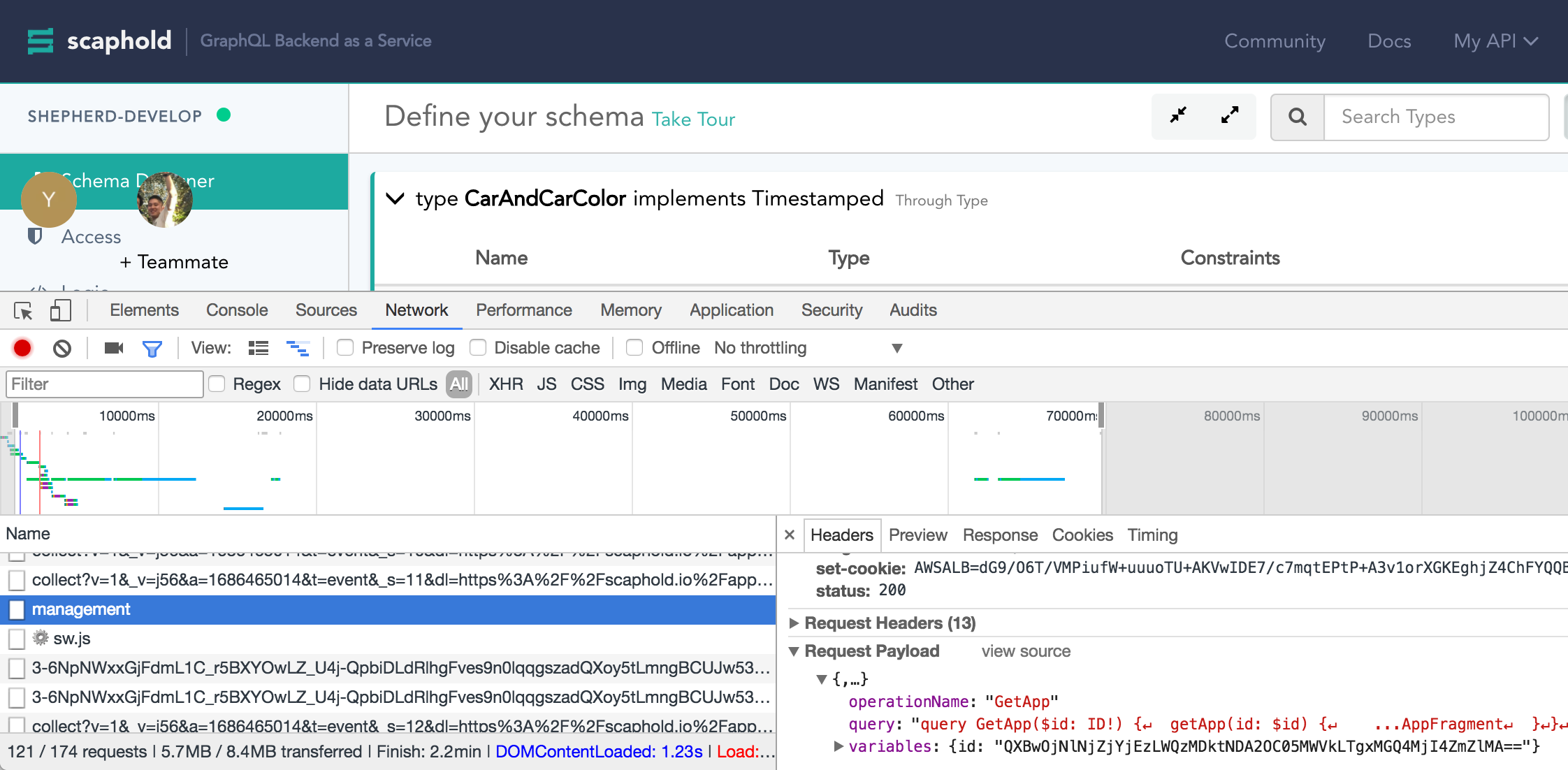
(↑ In above example the
idisQXBwOjNlNjZjYjEzLWQzMDktNDA2OC05MWVkLTgxMGQ4MjI4ZmZlMA==)
Optionally you can store the region and the appId in the non-standard
property scaphold in your package.json which looks something like this:
{
"scaphold": {
"endpoint": "<region>",
"apps": {
"<appName>": "<appId>"
}
}
}If you add this to the package.json then you can reduce the arguments to
the --appName.
Example: if the database is called housewarming then you simply add the
--appName option: scaphold-sync <operation> --appName housewarming.
Important: You also need a secret token! The secret token should never be stored in your project!
You will need to get it by hand from the scaphold backend:
In order for scaphold-sync to work, you will need to set the
environment variable SCAPHOLD_TOKEN. For example, like this:
env SCAPHOLD_TOKEN=0123456789ABCDEF scaphold-sync <operation> --appName housewarmingscaphold-sync exec - Executing Operations on Scaphold
The exec command is a key command. It allows a wide range of operations on
the scaphold database:
- CUD* operations of any type of data.
- CUD operations on type information of the data.
- CUD operations on logic functions and integration.
- Migration operations to do as many operations in bulk as possible.
* … There is no implementation of Read operations.
The exec command reads all operations as JSON data from stdin .
The JSON data is assumed to be an Array of operations that should be done
in series, one-by-one, after each-other.
Every entry is supposed to have one property which specifies the operation
that should be done. Example: The delete operation deletes a database entry.
It expects a type attribute to know which type of data you want to delete and
id to delete the specific id.
echo '[{"delete": {"type": "Role", "id": "fedcba9876543210"}}]' | scaphold-sync exec --appName houseewarming
Breakdown of the above example:
[{"delete": {"type": "Role", "id": "fedcba9876543210"}}] can be written like:
[
{
"delete": {
"type": "Role",
"id": "fedcba9876543210"
}
}
]With better formatting you see that the main Array contains one entry. And the
entry's only field is the delete field which will be used as operation.
The object of the delete operation will be used as parameter.
(Internal note:
It will use the ./lib/dbDel.js logic.)
echo '<data>' will output <data>.
<command-1> | <command-2> will redirect the output of <command-1> to the
stdin of <command-2>.
Which means that <data> (JSON data above) will be passed to the stdin of
scaphold-sync exec which will execute the delete operation.
Here is a list of operations supported and the types of data they operate with:
create- Creates one data entry. Thedatais supposed to be the input as specified in thescapholdschema. Needs atypeproperty to identify the type of the data entry.update- Updates one data entry. Thedatais supposed to be the input same as increate, but with anidproperty that tells it which entry to update.delete- Deletes one data entry. Thedatais supposed to be only anidfield and atypefor the logic to know what entry to delete.data- With anidit will do anupdate, else it willcreate. Similar to anupsertoperation in other databases.parallel- Runs operations in parallel. By default operations are run one-by-one. Any array passed as data will be executed in parallel. By default max limit is5operations will be run in parallel, you can increase this by passing a number after the--appIdlike this:scaphold-sync exec --appId housewarming --concurrency 20structure- Runs a structure change operation. Thedata, analogous to an exec operation can contain one of the following attributes.createIntegration- Creates a new Integration. ExpectsCreateIntegrationInputfrom the Migration API.updateIntegration- Updates an existing integration. ExpectsUpdateIntegrationInputfrom the Migration API.deleteIntegration- Deletes an existing integration. Expects just aStringwith the integration's name.createLogicFunction- Creates a new LogicFunction. ExpectsCreateLogicFunctionInputfrom the Migration API.updateLogicFunction- Updates an existing LogicFunction. ExpectsUpdateLogicFunctionInputfrom the Migration API.deleteLogicFunction- Deletes an existing LogicFunction. Expects to be just aStringwith theidof the LogicFunction.createType- Creates a new Type. ExpectsMigrateTypeInputfrom the Migration API.deleteType- Deletes an existing Type. Expects just aStringwith the name of the Type.updateType- Updates an existing Type. Note: Update is a complex operations. It will deeply inspect the given type data to make sure that necessary operations are done in the right order.replaceType- Replaces an existing Type with a different one. Some operations for types require that a type is deleted first before it is added again. One example might be: if the kind of the Type changes fromOBJECTtoENUM. Other than that it expects the same data asupdateType.
migration- Runs an Array of structure change operations. Will run a list of structure-change operations. This operation will try to re-arrange the operations in a way that occurs in the least actual operations.Example: If you have a
createLogicFunctionoperation that as a hook after the update of aFOO-Type. And you have acreateTypeoperation that creates theFOO-Type:migrationwould create theFOO-Type before it will create the LogicFunction, even if the order in the Array is otherwise.
scaphold-sync compare - Comparing the local schema to a scaphold db
This will load the schema definition in the ./schema folder and
compare all the Types and Integrations with the types currently existing in
the scaphold database. The output will be a list of operations needed for
scaphold-sync exec!
Important: the current implementation is dangerous! For example: If a field is renamed in the filesystem and the comparison is run it will record a deletion of the old field and the creation of a new field. Which means that you would loose the data in all the objects with that field.
There is currently no support for a different approach, be careful with changes in the structure!
Mapping of logicFunctions
LogicFunctions are a special case in the structure since they are treated
by scaphold as actual URL's but those URL's need to be different for every
deployment. This is why on different computers it is very likely that you
will see an update for every LogicFunction when you run this script the first
time on your computer even though nothing changed in the ./schema folder.
scaphold-sync down - Store the schema information in the ./schema folder
With down it will download all the current information on the scaphold setup
and store it in the ./schema folder in a custom format.
schema/app/[ --appName ]/integration/<integration-name>Holds all the integrations that are setup. Because they need to be different per Scaphold database, there is a folder for every integration.
schema/logicFunctions/<hook>.ymlHolds all the setups of LogicFunctions. This is separate from
typesbecause there are non-type-related hooks as well (i.e.migrateSchema).schema/types/<Type>.ymlAll the information on the customizable Types specified in Scaphold. Omits all the system types like
Nodethat can never be customized.schema/roles.ymlIn order to implement role-based permissions properly we need a copy of all the existing roles.
The format stored is not actually the same as the GraphQL types of the Migration API. It contains various changes that make it possible to sync it to different databases (i.e. the omission of id's). It will also transform the data to make it more comfortable to edit (i.e. fields in the GraphQL API are supposed to be Array's but its stored as a dictionary in the file system). It will omit properties that are sensible defaults and would spam the file system. (i.e. logicFunctions are usually POST urls, which is why the method is omitted if its POST).
By default it attempts to reduce problems with wrong ordering by sorting all keys alphabetically. At some places (specifically: the permissions), this is not possible which makes the permissions harder than other parts to edit consistently and can result in unnecessary git commits. If you happen edit the files by hand it is a good idea to try and stay in alphabetical order as well.
scaphold-sync stream - Running batch processes
exec will first read the entire JSON input and then execute each command.
This is good to ensure that the JSON input is well formatted but if you have
a large amount of operations stream is more efficient.
You can use stream like exec:
echo "[{...}]" | bin/scaphold-sync stream --appName housewarming --concurrency 20
But it uses JSONStream to process the statements and this will
read the array line-by-line. So, unlike in common JSON you need to make sure
that the JSON input is using one line for every statement. You can also make
it parallel by passing a concurrency parameter (20 in the above example).
AWS Support
It is recommended to have logic functions that work with Scaphold run in the same AWS-region as the Scaphold database (for performance reasons).
scaphold-sync supports Lambda functions through the serverless
framework. If the --cwd folder is a serverless project with
lambda functions and http endpoints, it supports both the deployment
and linking to logic functions!
Deploy mechanism
scaphold-sync deploy runs scaphold-sync compare which
generates a set of operations run through scaphold-sync exec.
Note: It will first run serverless deploy if it is a serverless project.
It will deploy the all lambda functions in the --stage called like
the --appName variable. And if your logic-functions are linked to relative
URLs it will prefix them to use the prefix of the endpoint.
Inconsistency Risks
The deployment process is significantly quicker than any manual process but it still takes a while to execute. Between the start of the Lambda update and the end of Scaphold update it might take a few minutes under which any requests to Scaphold will be using the new Lambda functions.
You can mitigate this by have many, small, deployments (which will be faster). You can also reduce the risk of problems by deploying in off-hours.
JavaScript API
const sync = require('scaphold-sync')
const options = {
// See CLI help for details on the options
appName: "--appName",
appId: "--appId",
concurrency: "--concurrency",
cwd: '--cwd',
schemaFolder: '--schemaFolder',
region: '--region'
}
const promise = sync(options, function (db) {
// In this handler you can use the db API. You will need to return
// a promise!
// Exec any database command
db.exec(concurrency, operation)
// Exec commands in parallel
db.execAll(concurrency, operations)
// Creates a CUD model for a scaphold type
db.getType(typeName)
// Creates an execution stream
db.createStream(defaultType, concurrency)
const structure = db.structure
// Loads the structure of the current scaphold app
structure.load()
// Compares the structure of the current scaphold app to a local folder
structure.compareToFolder(folder, concurrency)
// Downloads the app and stores it in a folder
structure.toFolder(folder)
// Executes all structure operations, the app can be the app returned by .load
structure.execAll(operations[, app])
// Executes one structure operations, the app can be the app returned by .load
structure.exec(operation[, app])
// All the operations above return a Promise! Make sure that you also
// return a promise to have clean async calls
return Promise.resolve({})
})contributions
All contributions in form of PR's or Issues are welcome!
This project is the result of an experiment which means there was no meaning to have tests at the time of first writing it. However, the project is structured in a way that should make the process of adding tests a breeze. If you can contribute tests they would be very welcome!
License
9 years ago