Starkdown


Starkdown is a Tiny <4kb Markdown parser written, almost as fast and smart as Tony Stark.
npm i starkdownMotivation
It is a continuation on a similar package called Snarkdown, which had stopped development at 1kb, but doesn't include basic support for paragraphs, tables, fenced divs, etc.
Starkdown stays around 1.6kb and adds these additional enhancements:
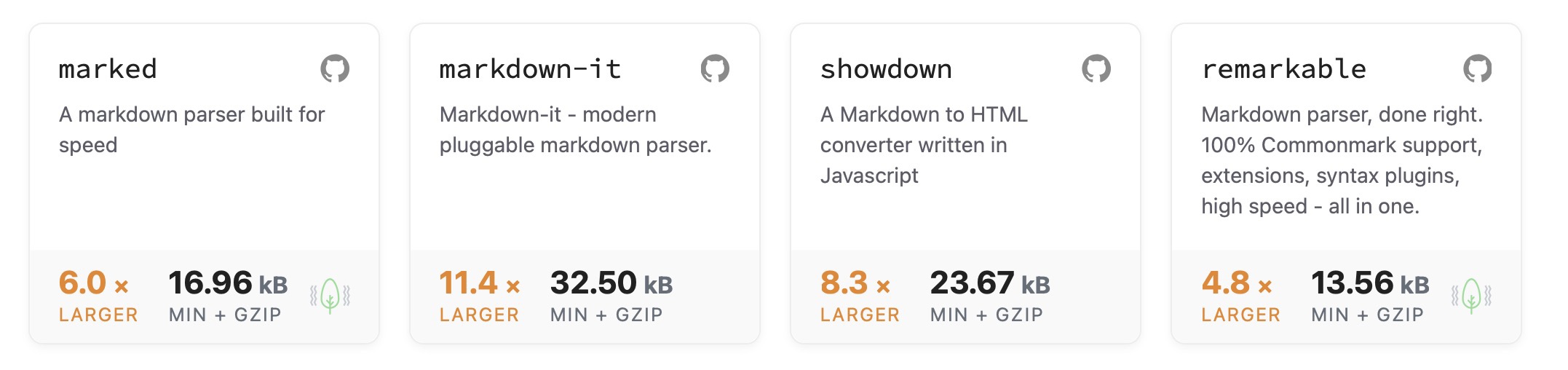
Package size wise, compared to other Markdown parsers, it's 8 ~ 18 times smaller! See the Package Size Comparison Chart
Usage
Starkdown is really easy to use, a single function which parses a string of Markdown and returns a String of HTML. Couldn't be simpler.
import { starkdown } from 'starkdown'
const str = '_This_ is **easy** to `use`.'
const html = starkdown(str)The html returned will look like:
<p><em>This</em> is <strong>easy</strong> to <code>use</code>.</p>Paragraphs
With most Markdown implementations, paragraphs are wrapped in <p> tags. With Starkdown, this is no different.
- All paragraphs and "inline" elements are wrapped in a
<p>tags (See List of "inline" elements on MDN)- Eg. a standalone image will still be wrapped in a
<p>tag, because it's an inline element.
- Eg. a standalone image will still be wrapped in a
- All non-inline elements will not be wrapped in
<p>tags- Eg. a table will not be wrapped in a
<p>tag.
- Eg. a table will not be wrapped in a
Check [github](https://github.com)
Img: converts to
<p>Check <a href="https://github.com">github</a></p>
<p>Img: <img src="/some-image.png" alt="" /></p>But also, when just using images and links:
[github](https://github.com)
converts to
<p><a href="https://github.com">github</a></p>
<p><img src="/some-image.png" alt="" /></p>In contrast, non-inline elements won't get a <p> tag:
### Code
\`\`\`js
const a = 1
\`\`\`converts to
<h3>Code</h3>
<pre class="code js"><code class="language-js">const a = 1</code></pre>Links
Usual markdown for links works, i.e
[github](https://github.com)becomes
<p><a href="https://github.com">github</a></p>But you can also add properties and classes to links using attribute lists like so:
[github](https://github.com){:target="\_blank" .foo .bar #baz}becomes
<p><a href="https://github.com" target="_blank" class="foo bar" id="baz">github</a></p>Tables
| My | Table |converts to
<table>
<tr>
<td>My</td>
<td>Table</td>
</tr>
</table>Fenced Divs
:::
this is some info
:::converts to
<div class="fenced"><p>this is some info</p></div>Or with a custom class.
::: info
this is some info
:::converts to
<div class="fenced info"><p>this is some info</p></div>Escaping snake_case words
You need to escape your formatting with \ in order to correctly convert sentences like these:
snake*case is \_so-so*will convert to:
<p>snake<em>case is </em>so-so</p>Instead you should write
snake*case is \_so-so*which will convert to:
<p>snake_case is <em>so-so</em></p>Disable MarkDown Features
Starkdown comes built in with several "parsers" that each are responsible to convert a part of the markdown to HTML. You can filter out certain parsers to get different results.
The list of enabled default parsers can be inspected at ./src/defaultParsers.ts.
import { starkdown, defaultParsers } from 'starkdown'
const str = '_This_ is **easy** to `use`.'
// implicitly uses defaultParsers
const html = starkdown(str)
// this is a quick way to parse the string without the table tokeniser
// however, even though the parser is not used, it will not get tree-shaked
const htmlWithoutTables = starkdown(str, {
plugins: defaultParsers.filter((x) => x.name !== 'table'),
})You can also add your own parsers this way. See #Custom Parsers below.
Tree-Shaking
You can slim down the import & bundle size of Starkdown if you don't need all of the parsers provided in Starkdown by default.
The list of default parsers can be inspected at ./src/defaultParsers.ts.
import { createTokenizerParser } from 'starkdown'
import { escape, boldItalicsStrikethrough, codeblocks, inlineCode, quote } from 'starkdown/parsers'
const str = '_This_ is **easy** to `use`.'
// This will tree-shake out any parser that is not used
const mdDiscordPlugins = [escape, boldItalicsStrikethrough, codeblock, inlineCode, quote]
const mdDiscord = createTokenizerParser(mdDiscordPlugins)
const html = mdDiscord(str, { plugins: mdDiscordPlugins })
// Note: These are in order of priority so the order can matter, e.g `escape` must come first to escape markdownYou can also add your own parsers this way. See #Custom Parsers below.
Custom Parsers
Parsers are defined as objects that match the following TypeScript definition.
import type { ParserDef } from 'starkdown'
// use this to create your custom parser- Check the source code of
ParserDeffor more info. - Examples can be found in the parsers folder.
Security
Note on XSS: Starkdown doesn't sanitize HTML. Please bring your own HTML sanitation for any place where user input will be converted into HTML.
Package Size Comparison Chart