Reactive Agents
A composable TypeScript framework for building reliable LLM agents on a harness you fully control. It wraps the agent loop — think, call a tool, observe, repeat — and keeps the loop finishing across model tiers while exposing every step as a typed event you can hook into. Three things it's built around:
- Reliable on every model tier. Tool-call healing, output verification, durable crash-resume, and a single-owner termination oracle let the same code finish the agent loop on a local 4B Ollama model and on Claude / GPT / Gemini.
- Transparent. A deterministic 12-phase execution engine with
before/after/on-errorhooks on every phase. Every prompt, tool call, and reasoning step is a typed event you can inspect, steer, and replay — locally, no SaaS dashboard required. - Composable. A typed builder of opt-in layers. Start with a model; add reasoning, 4-tier memory, guardrails, cost routing, and durability one
.with()call at a time.
Built on Effect-TS — schema-validated boundaries, tagged errors, no untyped throws.
| 41 packages & apps | 35 packages + 6 apps — 33 published to npm, all opt-in, no hidden coupling |
| 6 LLM providers | Anthropic, OpenAI, Gemini, Ollama (local), LiteLLM 40+, Test |
| 7 reasoning strategies | ReAct · Blueprint · Reflexion · Plan-Execute · Tree-of-Thought · Adaptive · Code-Action (@exp) |
| 6,854 tests · 851 files | Verified with bun test on every PR |
| 12-phase execution | Deterministic lifecycle with before/after/error hooks per phase |
| Cortex Studio | Live agent canvas, entropy charts, debrief UI, agent builder |
| Effect-TS end to end | Compile-time type safety, schema-validated boundaries, tagged errors |
![]()
![]()
![]()
Documentation · Discord · Quick Start · Features · Comparison · Architecture · Packages
Reliable on every tier — see it for yourself

The same agent investigates an incident, calls two tools, correlates the data, and recommends a fix — and finishes the job on a 4B local model just like on Claude. One builder, the only line that changes is the model. Demo source.
…and survives a crash mid-run

Durable execution: kill the process mid-run, and a fresh process reconstructs the run from its last on-disk checkpoint and finishes the job — completed tools never re-run. Demo source.
Why Reactive Agents?
Most AI agent frameworks are dynamically typed, monolithic, and opaque. They assume you're using GPT-4, break when you try smaller models, and hide every decision behind abstractions you can't inspect. Reactive Agents takes a fundamentally different approach:
| Problem | How We Solve It |
|---|---|
| No type safety | Effect-TS schemas validate every service boundary at compile time |
| Monolithic | 13 independent layers -- enable only what you need |
| Opaque decisions | 12-phase execution engine with before/after/error hooks on every phase |
| Model lock-in | Model-adaptive context profiles (4 tiers: local, mid, large, frontier) help smaller models punch above their weight |
| Single reasoning mode | 7 strategies (ReAct, Blueprint, Reflexion, Plan-Execute, Tree-of-Thought, Adaptive, Code-Action @experimental) |
| Unsafe by default | Guardrails block injection/PII/toxicity before the LLM sees input |
| No cost control | Complexity router picks the cheapest capable model; budget enforcement at 4 levels |
| Poor DX | Builder API chains capabilities in one place |
Cortex Studio
A full-featured local studio for live debugging — start it with .withCortex() or rax run --cortex:
Beacon view: live agent canvas — cognitive state, entropy signal, token usage per step
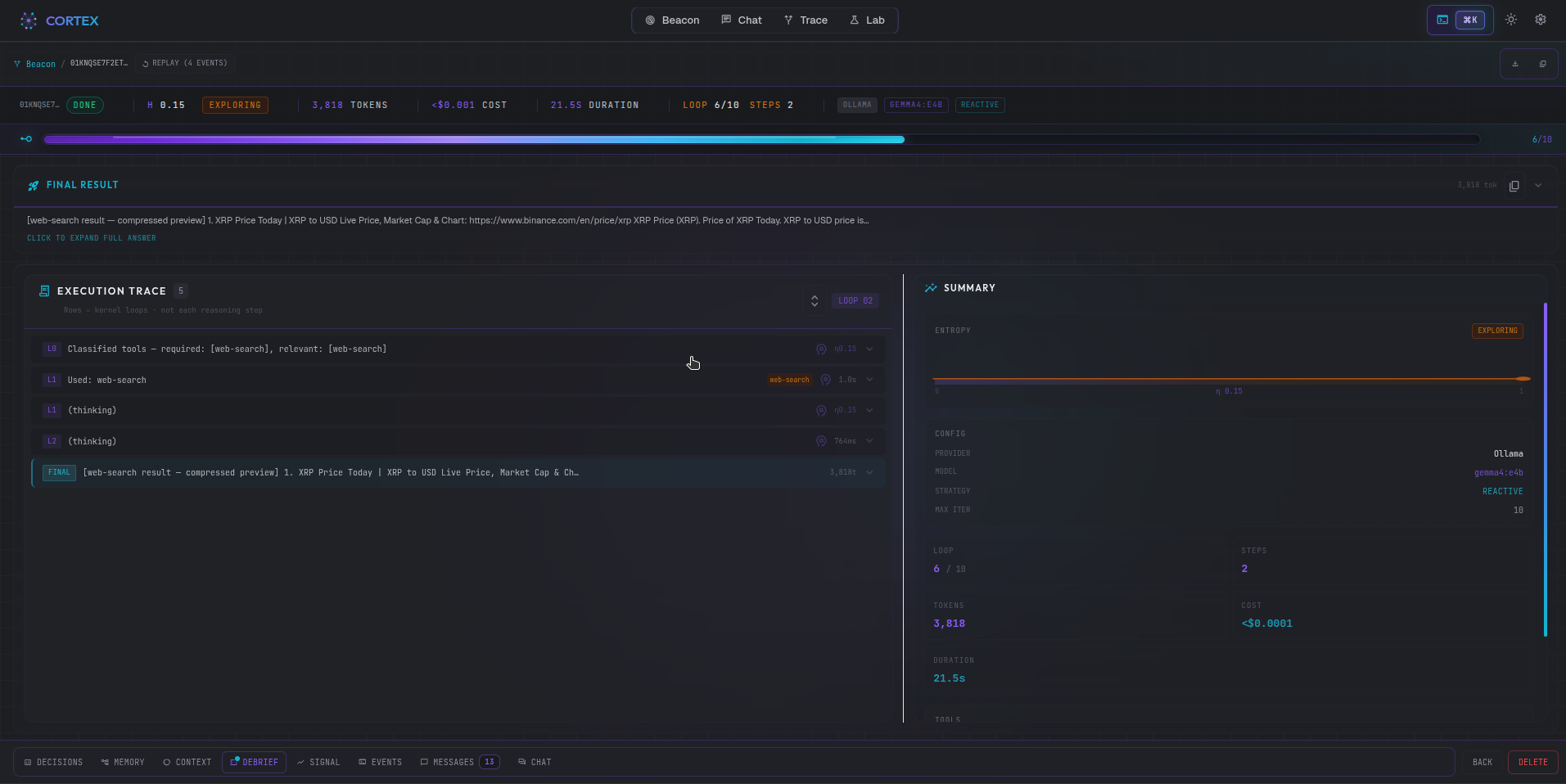
Run details: vitals strip, step-by-step execution trace, and AI-generated debrief summary
→ Full Cortex documentation with more screenshots
Features
Grouped by capability. Every layer is opt-in — call .with*() only for what you need.
Reasoning & Cognition
- 7 reasoning strategies + adaptive meta-strategy: ReAct, Blueprint (efficient static-decomposable), Reflexion, Plan-Execute, Tree-of-Thought, Adaptive, Code-Action (@experimental)
- Intelligent context synthesis — fast-template or deep-LLM transcript shaping per iteration (
ContextSynthesizedon EventBus) - Reactive intelligence — 5-source entropy sensor + 8-action controller (early-stop, compress, switch strategy, adjust temp, inject tool, activate skill, redirect on failure, stall-detect) + Thompson Sampling bandit
- Adaptive calibration — three-tier live learning (shipped prior → community profile → local posterior) with per-run observations and classifier bypass
Memory & Skills
- 4-layer memory — working, episodic, semantic (vector + FTS5), procedural — backed by
bun:sqlitewith background consolidation + decay - ExperienceStore — cross-agent learning loop closed by
ToolCallObservation - Living Skills System — agentskills.io
SKILL.mdcompatible, SQLite-backed, LLM-refined evolution, 5-stage compression, context-aware injection guard - Agent debrief + chat —
agent.chat()for one-shot Q&A,agent.session()for multi-turn (optional SQLite persistence), post-runDebriefSynthesizer
Providers & Models
- 6 LLM providers — Anthropic, OpenAI, Google Gemini, Ollama (local), LiteLLM (40+ models), Test (deterministic)
- Model-adaptive context profiles — 4 tiers (local / mid / large / frontier) with tier-aware prompts, compaction, and truncation; 4B+ Ollama models work with the same code
- Adaptive tool calling — FC dialect probe routes to
NativeFCDriveror 3-tierTextParseDriver(XML / JSON / pseudo-code) - HealingPipeline — normalizes tool-name aliases, param aliases, paths, and type coercion before every execution (86.7% recovery rate, +80pp accuracy on small models)
- Provider fallback chains —
withFallbacks()for graceful degradation across providers and models - Native thinking mode —
.withThinking({ effort, budgetTokens })opts into provider-native reasoning across all four cloud/local adapters (off unless enabled);.withModel({ thinking: true })is the quick boolean - Cost-aware model routing —
.withModelRouting()(opt-in, off by default) routes each run to the cheapest capable model of the configured provider by task complexity, degrading to the configured model on any error
Production Safety
- Guardrails — pre-LLM injection detection, PII filtering, toxicity blocking, kill switch, behavioral contracts
- Ed25519 identity — real cryptographic agent certificates, RBAC, delegation chains, audit trails
- Verification — semantic entropy, fact decomposition, NLI hallucination detection
- Fabrication guard —
.withFabricationGuard()is on by default; rejects invented empirical performance measurements (benchmark timings, % speed-ups) absent from the tool-observation corpus. Soften to"warn"or disable with"off" - Stall / no-progress policy —
.withStallPolicy()bounds wasted iterations when the model ignores required-tool nudges: fast-escalate after N ignored nudges instead of looping to the full cap (progress resets the streak) - Harness-forced abstention — when grounding is structurally impossible (a required tool is missing, or synthesis is repeatedly rejected as ungrounded), the run ends honestly with
terminatedBy: "abstained"andresult.abstention { reason, missing }instead of fabricating or grinding tomax_iterations - Cost controls — 27-signal complexity router, semantic cache, budget enforcement (persists across restarts), dynamic pricing via OpenRouter
- Required tools guard — ensure critical tools are called before answering, with
maxCallsPerToolbudgets to prevent research loops
Observability
- 12-phase execution engine — deterministic lifecycle with
before/after/on-errorhooks per phase - Professional metrics dashboard — EventBus-driven execution timeline, tool-call summary, cost estimation, smart alerts (zero manual instrumentation)
- Distributed tracing (OTLP) + structured logging via
withLogging({ level, format, filePath }) - Cortex Studio live reporting —
.withCortex(url?)streams runtime telemetry over WebSocket - Streaming + SSE —
agent.runStream()withAbortSignalcancellation; one-line SSE endpoint viaAgentStream.toSSE()
Composition & Multi-Agent
- Builder API — chains capabilities in one place; Agent-as-data via
toConfig()/fromJSON()for save/share/restore - Two-line entry point —
ReactiveAgents.quick()resolves provider, model, and iteration defaults from the environment and returns a ready-to-run agent - Functional combinators —
agentFn(),pipe(),parallel(),race()for declarative agent pipelines - A2A protocol — Agent Cards, JSON-RPC 2.0 server/client, SSE streaming, agent-as-tool
- Orchestration — sequential, parallel, pipeline, map-reduce; dynamic sub-agent spawning with depth limits
- Persistent gateway — adaptive heartbeats, cron scheduling, webhook ingestion (GitHub adapter), composable policy engine, chat mode with per-sender SQLite session history
Builder Hardening
withStrictValidation(),withTimeout(),withLlmTimeout()(per-LLM-call timeout for local/Ollama providers — tolerate cold model loads without loosening the run-level timeout),withRetryPolicy(),withCacheTimeout(),withErrorHandler(),withFallbacks(),withLogging(),withHealthCheck(),withMinIterations(),withVerificationStep(),withOutputValidator(),withCustomTermination(),withProgressCheckpoint(),withTaskContext()defineTooltyped tool authoring — Standard Schema input (Effect Schema / Zod / Valibot / ArkType) + a plain async handler with arg types inferred from the schema; malformed options (parameters/executeinstead ofinput/handler) fail fast with a typed error- ToolBuilder fluent API — define tools without raw schema objects
- Dynamic tool registration —
agent.registerTool()/agent.unregisterTool()at runtime
Frontend Integration
@reactive-agents/react—useAgentStream,useAgenthooks@reactive-agents/vue— Vue 3 composables with reactive refs@reactive-agents/svelte— Svelte 4/5 writable stores- All consume
AgentStream.toSSE()from Next.js, SvelteKit, Nuxt, or any SSE-capable server
Confidence
- 6,854 tests across 851 files — verified
bun teston every PR - Strict TypeScript — Effect-TS schemas validate every service boundary; explicit tagged errors, no untyped throws
Quick Start
Install and run your first TypeScript AI agent in under 60 seconds.
Recommended: Bun ≥1.0.0 — optimal performance with native SQLite, subprocess, and HTTP APIs. Node.js 22.5+ is now also supported via
@reactive-agents/runtime-shim— same code, both runtimes. Install Bun:curl -fsSL https://bun.sh/install | bash
# Bun (recommended)
bun add reactive-agents
# Node.js 22.5+
npm install reactive-agentsNote:
effectis included as a dependency ofreactive-agentsand installed automatically. If you import fromeffectdirectly in your own code (e.g.import { Effect } from "effect"), add it to your project explicitly:bun add effect(ornpm install effect).
import { ReactiveAgents } from 'reactive-agents'
const agent = await ReactiveAgents.create()
.withName('assistant')
.withProvider('anthropic')
.withModel('claude-sonnet-4-6')
.build()
const result = await agent.run('Explain quantum entanglement')
console.log(result.output)
console.log(result.metadata) // { duration, cost, tokensUsed, stepsCount }Add Capabilities
The canonical composition path is a HarnessProfile preset — lean(),
balanced(), or intelligent(). Presets compose the registry's
default-on capability set in one line:
import { ReactiveAgents, HarnessProfile } from 'reactive-agents'
const agent = await ReactiveAgents.create()
.withName('research-agent')
.withProvider('anthropic')
.withProfile(HarnessProfile.balanced()) // memory + RI + verifier + strategy switching
.withTools() // built-in tools + MCP
.withMaxIterations(15)
.withBudget({ tokenLimit: 100_000 }) // canonical budget killswitch
.build()Pick the preset that matches the workload:
HarnessProfile.lean()— model + nothing else. Latency- and cost-sensitive paths; benchmark ablations.HarnessProfile.balanced()— today's production defaults (memory + reactive intelligence + verifier + strategy switching).HarnessProfile.intelligent()— balanced + skill persistence for cross-session compounding learning.
Override specific capabilities after the preset — order matters; later
calls win. The individual .withX() methods are fully supported and
compose cleanly with presets; reach for a preset when you want the whole
default-on set in one line, or .compose(...) for a precise chokepoint.
const agent = await ReactiveAgents.create()
.withName('research-agent')
.withProvider('anthropic')
.withProfile(HarnessProfile.intelligent()) // cross-session skills
.withMemory({ tier: 'enhanced' }) // upgrade memory to vector embeddings
.withTools()
.withGateway({ // persistent autonomous harness
heartbeat: { intervalMs: 1_800_000, policy: 'adaptive' },
crons: [{ schedule: '0 9 * * MON', instruction: 'Weekly review' }],
policies: { dailyTokenBudget: 50_000 },
})
.compose((h) => h.before('act', logFn)) // canonical chokepoint composition
.build()Conversational Chat
Use agent.chat() for single-turn Q&A or agent.session() for multi-turn conversations with adaptive routing -- direct LLM for simple questions, full ReAct loop for tool-capable queries:
// Single-turn chat
const answer = await agent.chat("What's the status of the deployment?")
// Multi-turn session
const session = agent.session()
await session.chat("Summarize yesterday's logs")
await session.chat('Which errors were most frequent?')Agent Config (Agent as Data)
Define agents as JSON-serializable config objects. Save, share, and reconstruct agents without code:
import {
agentConfigToJSON,
agentConfigFromJSON,
ReactiveAgents,
} from 'reactive-agents'
// Builder → Config → JSON
const builder = ReactiveAgents.create()
.withName('researcher')
.withProvider('anthropic')
.withReasoning({ defaultStrategy: 'plan-execute-reflect' })
.withTools({ adaptive: true })
.withMemory({ tier: 'enhanced' })
const config = builder.toConfig()
const json = agentConfigToJSON(config)
// Save to file, database, or send over the wire
// JSON → Builder → Agent
const restored = await ReactiveAgents.fromJSON(json)
const agent = await restored.build()
const result = await agent.run('Research quantum computing advances')Composition API
Build agent pipelines with functional combinators:
import { agentFn, pipe, parallel, race } from 'reactive-agents'
// Create lazy agent functions
const researcher = agentFn({ name: 'researcher', provider: 'anthropic' }, (b) =>
b.withReasoning().withTools()
)
const summarizer = agentFn({ name: 'summarizer', provider: 'anthropic' })
// Sequential pipeline: research → summarize
const pipeline = pipe(researcher, summarizer)
const result = await pipeline('What are the latest AI breakthroughs?')
// Parallel fan-out: run multiple analyses concurrently
const multiAnalysis = parallel(
agentFn({ name: 'sentiment', provider: 'anthropic' }),
agentFn({ name: 'keywords', provider: 'anthropic' }),
agentFn({ name: 'summary', provider: 'anthropic' })
)
const combined = await multiAnalysis('Article text here...')
// combined.output contains labeled results from all 3 agents
// Race: fastest agent wins
const fastest = race(
agentFn({ name: 'claude', provider: 'anthropic' }),
agentFn({ name: 'gpt4', provider: 'openai' })
)
const winner = await fastest('Quick answer needed')
// Clean up
await pipeline.dispose()
await multiAnalysis.dispose()
await fastest.dispose()Streaming
Tokens arrive as they're generated via AsyncGenerator. Pass an AbortSignal to cancel mid-stream:
const controller = new AbortController()
for await (const event of agent.runStream('Analyze this dataset', {
signal: controller.signal,
})) {
if (event._tag === 'TextDelta') process.stdout.write(event.text)
if (event._tag === 'IterationProgress')
console.log(`Step ${event.iteration}/${event.maxIterations}`)
if (event._tag === 'StreamCancelled') console.log('Stream cancelled')
if (event._tag === 'StreamCompleted') {
console.log('\nDone!')
// event.toolSummary: Array<{ toolName, calls, successRate }>
}
}
// Cancel from elsewhere (e.g., HTTP request abort)
controller.abort()Lifecycle Hooks
Intercept any of the 12 execution phases with before, after, or error hooks:
import { Effect } from 'effect'
import { ReactiveAgents } from 'reactive-agents'
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withTools()
.withHook({
phase: 'think',
timing: 'after',
handler: (ctx) => {
console.log(
`Step ${ctx.metadata.stepsCount}: ${ctx.metadata.strategyUsed}`
)
return Effect.succeed(ctx)
},
})
.withHook({
phase: 'act',
timing: 'after',
handler: (ctx) => {
const last = ctx.toolResults.at(-1) as
| { toolName?: string }
| undefined
if (last?.toolName) console.log(`Tool called: ${last.toolName}`)
return Effect.succeed(ctx)
},
})
.build()Available phases (12): bootstrap, guardrail, cost-route, strategy-select, think, act, observe, verify, memory-flush, cost-track, audit, complete. Each supports before, after, and on-error timing.
Comparison
How Reactive Agents compares to other TypeScript agent frameworks on shipped, working features:
| Capability | Reactive Agents | LangChain JS | Vercel AI SDK | Mastra |
|---|---|---|---|---|
| Full type safety (Effect-TS) | Yes | -- | Partial | Partial |
| Composable layer architecture | 13 layers | -- | -- | -- |
| Reasoning strategies | 6 (+ @exp code-action) | Multiple | Partial | 1 |
| Model-adaptive context | 4 tiers | -- | -- | -- |
| Local model optimization | Yes | -- | -- | -- |
| Execution lifecycle hooks | 12 phases | Callbacks | Middleware | -- |
| Multi-agent orchestration | A2A + workflows | Yes | Partial | Yes |
| Token streaming | Yes | Yes | Yes | Yes |
| Production guardrails | Yes | -- | -- | -- |
| Cost tracking + budgets | Yes | -- | -- | -- |
| Persistent gateway | Yes | -- | -- | -- |
| Agent debrief + chat | Yes | -- | -- | -- |
| Metrics dashboard | Yes | LangSmith | -- | -- |
| Agent-as-data config | Yes | -- | -- | -- |
| Functional composition | Yes | Yes | -- | -- |
| Dynamic tool registration | Yes | Yes | -- | -- |
| Test suite | 6,854 tests | -- | -- | -- |
Reflects our understanding of each framework's first-party, shipped features as of 2026-06. -- means we found no first-party equivalent, not that none exists. Corrections welcome — open a PR.
Use Cases
- Autonomous engineering agents with tool execution and code generation
- Research and reporting workflows with verifiable reasoning steps
- Scheduled background agents using heartbeats, cron jobs, and webhooks
- Secure enterprise copilots with RBAC, audit trails, and policy controls
- Hybrid local/cloud AI deployments with adaptive context profiles
- Multi-agent teams with A2A protocol and dynamic sub-agent delegation
Architecture
ReactiveAgentBuilder
-> createRuntime()
-> Core Services EventBus, AgentService, TaskService
-> LLM Provider Anthropic, OpenAI, Gemini, Ollama, LiteLLM, Test
-> Memory Working, Semantic, Episodic, Procedural
-> Reasoning ReAct, Reflexion, Plan-Execute, ToT, Adaptive
-> Tools Registry, Sandbox, MCP Client
-> Guardrails Injection, PII, Toxicity, Kill Switch, Behavioral Contracts
-> Verification Semantic Entropy, Fact Decomposition, NLI
-> Cost Complexity Router, Budget Enforcer, Cache
-> Identity Certificates, RBAC, Delegation, Audit
-> Observability Tracing, Metrics, Structured Logging
-> Interaction 5 Modes, Checkpoints, Preference Learning
-> Orchestration Sequential, Parallel, Pipeline, Map-Reduce
-> Prompts Template Engine, Version Control
-> Gateway Heartbeats, Crons, Webhooks, Policy Engine
-> ExecutionEngine 12-phase lifecycle with hooksEvery layer is an Effect Layer -- composable, independently testable, and tree-shakeable.
12-Phase Execution Engine
Every task flows through a deterministic lifecycle. Each phase calls its corresponding service when enabled:
Bootstrap --> Guardrail --> Cost Route --> Strategy Select
|
+--------------------+
| Think -> Act -> Observe | <-- loop
+--------------------+
|
Verify --> Memory Flush --> Cost Track --> Audit --> Complete| Phase | Service Called | What It Does |
|---|---|---|
| Bootstrap | MemoryService | Load context from semantic/episodic memory |
| Guardrail | GuardrailService | Block unsafe input before LLM sees it |
| Cost Route | CostService | Select optimal model tier by complexity |
| Strategy Select | ReasoningService | Pick reasoning strategy (or direct LLM) |
| Think/Act/Observe | LLMService + ToolService | Reasoning loop with real tool execution |
| Verify | VerificationService | Fact-check output (entropy, decomposition, NLI) |
| Memory Flush | MemoryService | Persist session + episodic memories |
| Cost Track | CostService | Record spend against budget |
| Audit | ObservabilityService | Log audit trail (tokens, cost, strategy, duration) |
| Complete | -- | Build final result with metadata |
Every phase supports before, after, and on-error lifecycle hooks. When observability is enabled, every phase emits trace spans and metrics.
Reasoning Strategies
| Strategy | How It Works | Best For |
|---|---|---|
| ReAct | Think -> Act -> Observe loop | Tool use, step-by-step tasks |
| Reflexion | Generate -> Critique -> Improve | Quality-critical output |
| Plan-Execute | Plan steps -> Execute -> Reflect -> Refine | Structured multi-step work |
| Tree-of-Thought | Branch -> Score -> Prune -> Synthesize | Creative, open-ended problems |
| Adaptive | Analyze task -> Auto-select best strategy | Mixed workloads |
Code-Action @exp |
LLM generates a TypeScript IIFE run in a Worker sandbox; tools exposed as async functions | Multi-tool orchestration, pure computation |
// Auto-select the best strategy per task
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning({ defaultStrategy: 'adaptive' })
.build()
// Strategy switching is on by default — customize or disable explicitly
const agent2 = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning({
// enableStrategySwitching defaults to true
maxStrategySwitches: 1,
fallbackStrategy: 'plan-execute-reflect',
})
.build()Multi-Provider Support
| Provider | Models | Tool Calling | Streaming |
|---|---|---|---|
| Anthropic | Claude Haiku, Sonnet, Opus | Yes | Yes |
| OpenAI | GPT-4o, GPT-4o-mini | Yes | Yes |
| Google Gemini | Gemini Flash, Pro | Yes | Yes |
| Ollama | Any local model | Yes | Yes |
| LiteLLM | 40+ models via LiteLLM proxy | Yes | Yes |
| Test | Mock (deterministic) | -- | -- |
Switch providers with one line -- agent code stays the same.
Model-Adaptive Context
Optimize prompt construction and context compaction for your model tier:
const agent = await ReactiveAgents.create()
.withProvider('ollama')
.withModel('qwen3:4b')
.withReasoning()
.withTools()
.withContextProfile({ tier: 'local' }) // Lean prompts, aggressive compaction
.build()| Tier | Models | Context Strategy |
|---|---|---|
"local" |
Ollama small models (<=14b) | Lean prompts, aggressive compaction after 6 steps, 800-char truncation |
"mid" |
Mid-range models | Balanced prompts, moderate compaction |
"large" |
Anthropic, OpenAI, Gemini | Full context, standard compaction |
"frontier" |
Flagship models | Maximum context, minimal compaction |
Context Window Override (numCtx)
Pin the exact context window the provider is given, instead of relying on the
model's assumed maximum. Pass it via the .withModel() object form:
const agent = await ReactiveAgents.create()
.withProvider('ollama')
.withModel({ model: 'qwen3:4b', numCtx: 32768 }) // exact num_ctx sent to Ollama
.withReasoning()
.build()numCtx is also a first-class AgentConfig field, so it round-trips through
toConfig() / fromJSON() and the Cortex Studio agent builder:
{ "provider": "ollama", "model": "qwen3:4b", "numCtx": 32768 }Provider applicability: honored by providers that expose a context-window knob
(Ollama maps it to num_ctx). Cloud providers that don't expose one ignore the
field. When set, it becomes the authoritative denominator for the context-usage
gauge in Cortex Studio.
Packages
| Package | Description |
|---|---|
@reactive-agents/core |
EventBus pub/sub, AgentService lifecycle, TaskService state machine, canonical types |
@reactive-agents/runtime |
12-phase ExecutionEngine, ReactiveAgentBuilder, createRuntime() layer composer |
@reactive-agents/llm-provider |
Unified LLM interface for Anthropic, OpenAI, Gemini, Ollama, LiteLLM, and Test providers |
@reactive-agents/memory |
4-layer memory (working, semantic, episodic, procedural) on bun:sqlite; ExperienceStore cross-agent learning; background consolidation + decay |
@reactive-agents/reasoning |
7 strategies (ReAct, Blueprint, Reflexion, Plan-Execute, ToT, Adaptive, Code-Action @experimental) with composable kernel architecture |
@reactive-agents/tools |
Tool registry with sandboxed execution, MCP client, agent-as-tool adapter, dynamic sub-agent spawning |
@reactive-agents/guardrails |
Pre-LLM safety: injection detection, PII filtering, toxicity blocking |
@reactive-agents/verification |
Post-LLM quality: semantic entropy, fact decomposition, NLI hallucination detection |
@reactive-agents/cost |
27-signal complexity routing, per-execution budget enforcement, semantic cache |
@reactive-agents/identity |
Ed25519 agent certificates, RBAC policies, delegation chains, audit logging |
@reactive-agents/observability |
Distributed tracing (OTLP), MetricsCollector, structured logging, console + JSON exporters |
@reactive-agents/interaction |
5 autonomy modes, checkpoint/resume, approval gates, preference learning |
@reactive-agents/orchestration |
Multi-agent workflows: sequential, parallel, pipeline, map-reduce with A2A support |
@reactive-agents/prompts |
Version-controlled template engine with variable interpolation and prompt library |
@reactive-agents/eval |
Evaluation framework: LLM-as-judge scoring, EvalStore persistence, comparison reports |
@reactive-agents/a2a |
A2A protocol: Agent Cards, JSON-RPC 2.0 server/client, SSE streaming |
@reactive-agents/gateway |
Persistent autonomous harness: adaptive heartbeats, cron scheduling, webhook ingestion, composable policy engine |
@reactive-agents/testing |
Mock services (LLM, tools, EventBus), assertion helpers, deterministic test fixtures |
@reactive-agents/benchmarks |
Benchmark suite: 20 tasks x 5 tiers, overhead measurement, report generation |
@reactive-agents/health |
Health checks and readiness probes for production deployments |
@reactive-agents/reactive-intelligence |
Metacognitive layer: entropy sensor (5 sources), reactive controller (early-stop, compression, strategy switch), learning engine (calibration, bandit, skill synthesis), telemetry client |
@reactive-agents/react |
React 18+ hooks: useAgentStream (token streaming), useAgent (one-shot) — consume AgentStream.toSSE() endpoints |
@reactive-agents/vue |
Vue 3 composables: useAgentStream, useAgent with reactive refs |
@reactive-agents/svelte |
Svelte 4/5 stores: createAgentStream, createAgent writable stores |
@reactive-agents/observe |
Zero-config OpenTelemetry tracing — maps AgentStarted/Completed, LLMRequest*, and ToolCall* events to OpenInference-compliant OTLP spans |
@reactive-agents/replay |
Deterministic trace replay — record any run to a snapshot file, re-run with different model/prompt without re-calling the LLM; supports strict/lenient mode and diffTraces |
@reactive-agents/runtime-shim |
Cross-runtime adapter — lets the framework run on Node.js 22.5+ in addition to Bun; provides unified Database, spawn, serve, and file I/O primitives |
create-reactive-agent |
Project scaffolder — bunx create-reactive-agent my-app generates a runnable agent project with template, provider, and package-manager selection |
Branch preview (not on main yet): feat/channels-package adds @reactive-agents/channels, runtime .withChannels(), and renames gateway channels → accessControl for sender policy vs chat mode. Summary: wiki/Research/Debriefs/2026-05-03-channels-phase1-development-debrief.md.
Observability & Metrics Dashboard
When observability is enabled, the agent displays a professional metrics dashboard after each execution:
+-------------------------------------------------------------+
| Agent Execution Summary |
+-------------------------------------------------------------+
| Status: Success Duration: 13.9s Steps: 7 |
| Tokens: 1,963 Cost: ~$0.003 Model: claude-3.5 |
+-------------------------------------------------------------+
Execution Timeline
|- [bootstrap] 100ms ok
|- [think] 10,001ms warn (7 iter, 72% of time)
|- [act] 1,000ms ok (2 tools)
|- [complete] 28ms ok
Tool Execution (2 called)
|- file-write ok 3 calls, 450ms avg
|- web-search ok 2 calls, 280ms avg- Per-phase execution timing and bottleneck identification
- Tool call summary (success/error counts, average duration)
- Smart alerts and optimization tips
- Cost estimation in USD
- EventBus-driven collection (no manual instrumentation)
Enable with:
.withObservability({ verbosity: "normal", live: true })CLI (rax)
rax init my-project --template full # Scaffold a project
rax create agent researcher --recipe researcher # Generate an agent from recipe
rax create agent my-agent --interactive # Interactive scaffolding (readline prompts)
rax run "Explain quantum computing" --provider anthropic # Run an agent
rax cortex # Cortex studio (after: bun add @reactive-agents/cortex)
bun cortex # Cortex API + Vite UI (source-repo contributors)
rax run "Task" --cortex --provider anthropic # Stream events to Cortex (.withCortex())Register Custom Tools
Tools are registered at build time, via agent.registerTool() after build(), or through MCP. Built-in task tools include web search, file I/O, HTTP, and code execution; dynamic sub-agents add spawn-agent. With .withTools(), the Conductor's Suite also injects recall, find, brief, and pulse (override with .withMetaTools(false)).
Use defineTool — a schema plus a plain async handler with arg types inferred from the schema. input accepts an Effect Schema.Struct or any Standard Schema (Zod / Valibot / ArkType):
import { ReactiveAgents } from 'reactive-agents'
import { defineTool } from '@reactive-agents/tools'
import { Schema } from 'effect'
const webSearchTool = defineTool({
name: 'web_search',
description: 'Search the web for current information',
input: Schema.Struct({ query: Schema.String }),
// args is typed as { query: string }
handler: async (args) => `Results for: ${args.query}`,
})
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withTools({ tools: [webSearchTool] })
.build()Or the ToolBuilder fluent API to define tools without raw schema objects:
import { ToolBuilder } from '@reactive-agents/tools'
import { Effect } from 'effect'
const webSearchTool = ToolBuilder.create('web_search')
.description('Search the web for current information')
.param('query', 'string', 'Search query', { required: true })
.riskLevel('low')
.timeout(10_000)
.handler((args) => Effect.succeed(`Results for: ${args.query}`))
.build()Or use raw schema objects directly:
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withTools({
tools: [
{
definition: {
name: 'web_search',
description: 'Search the web for current information',
parameters: [
{
name: 'query',
type: 'string',
description: 'Search query',
required: true,
},
],
riskLevel: 'low',
timeoutMs: 10_000,
requiresApproval: false,
source: 'function',
},
handler: (args) => Effect.succeed(`Results for: ${args.query}`),
},
],
})
.build()Dynamic Tool Registration
Add or remove tools from a running agent at runtime:
import { Effect } from 'effect'
const agent = await ReactiveAgents.create()
.withName('adaptive-agent')
.withProvider('anthropic')
.withReasoning()
.withTools()
.build()
// Register a new tool at runtime
await agent.registerTool(
{
name: 'custom_api',
description: 'Call the custom API',
parameters: [
{
name: 'endpoint',
type: 'string',
description: 'API endpoint',
required: true,
},
],
riskLevel: 'low',
source: 'function',
},
(args) => Effect.succeed(`Response from ${args.endpoint}`)
)
// Later, remove it when no longer needed
await agent.unregisterTool('custom_api')Dynamic Sub-Agent Spawning
Use .withDynamicSubAgents() to let the model spawn ad-hoc sub-agents at runtime without pre-configuring named agent tools. This registers the built-in spawn-agent tool, which the model can invoke freely:
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withModel('claude-sonnet-4-6')
.withTools()
.withDynamicSubAgents({ maxIterations: 5 })
.build()Sub-agents receive a clean context window, inherit the parent's provider and model by default, and are depth-limited to MAX_RECURSION_DEPTH = 3.
| Approach | When to use |
|---|---|
.withAgentTool("name", config) |
Named, purpose-built sub-agent with a specific role |
.withDynamicSubAgents() |
Ad-hoc delegation at model's discretion, unknown tasks |
MCP (Model Context Protocol)
Connect any MCP-compatible server — 9,400+ public servers covering filesystem, GitHub, Slack, browsers, databases, and more. Use .withMCP() for each server you need:
import { ReactiveAgents } from 'reactive-agents'
// stdio transport — subprocess communicates via JSON-RPC over stdin/stdout
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withMCP({
name: 'filesystem',
transport: 'stdio',
command: 'bunx',
args: ['-y', '@modelcontextprotocol/server-filesystem', '.'],
})
.withMCP({
name: 'github',
transport: 'stdio',
command: 'bunx',
args: ['-y', '@modelcontextprotocol/server-github'],
env: { GITHUB_PERSONAL_ACCESS_TOKEN: process.env.GH_TOKEN ?? '' },
})
.build()
// Streamable HTTP transport — modern cloud-hosted MCP servers
const agent2 = await ReactiveAgents.create()
.withProvider('anthropic')
.withMCP({
name: 'stripe',
transport: 'streamable-http',
endpoint: 'https://mcp.stripe.com',
headers: { Authorization: `Bearer ${process.env.STRIPE_SECRET_KEY}` },
})
.build()MCP tools appear in the tool registry alongside custom tools — the LLM sees them all uniformly. Mix MCP servers with ToolBuilder custom tools in the same agent. See full MCP docs.
Testing
Built-in test scenario support for deterministic, offline tests:
const agent = await ReactiveAgents.create()
.withTestScenario([
{ match: 'capital of France', text: 'Paris is the capital of France.' },
])
.build()
const result = await agent.run('What is the capital of France?')
// result.output -> "Paris is the capital of France."The @reactive-agents/testing package includes streaming assertions and pre-built scenario fixtures:
import {
expectStream,
createGuardrailBlockScenario,
createBudgetExhaustedScenario,
} from '@reactive-agents/testing'
// Stream assertions
const stream = agent.runStream('Write a haiku')
await expectStream(stream)
.toEmitTextDeltas()
.toComplete()
.toEmitEvents(['TextDelta', 'StreamCompleted'])
// Pre-built scenario fixtures
const scenario = createGuardrailBlockScenario() // agent + prompt that triggers guardrail
const budget = createBudgetExhaustedScenario() // agent + prompt that exhausts budget
const maxIter = createMaxIterationsScenario() // agent + prompt that hits max iterationsDevelopment
bun install # Install dependencies
bun test # Run full test suite (6,854 tests / 851 files, ~95s)
bun run build # Build all packages (ESM + DTS via tsup)Environment Variables
ANTHROPIC_API_KEY=sk-ant-... # Anthropic Claude
OPENAI_API_KEY=sk-... # OpenAI GPT-4o
GOOGLE_API_KEY=... # Google Gemini
EMBEDDING_PROVIDER=openai # For vector memory
EMBEDDING_MODEL=text-embedding-3-small
LLM_DEFAULT_MODEL=claude-sonnet-4-6Documentation
Full documentation at docs.reactiveagents.dev
- Getting Started -- Build an agent in 5 minutes
- Reasoning Strategies -- All 7 strategies explained
- Architecture -- Layer system deep dive
- Cookbook -- Testing, multi-agent patterns, production deployment
Used By
Reactive Agents is in early access. If you're using it in production or a research project, open a PR adding your name here, or drop a note in Discussions.
Your team here.
Roadmap
Public milestone tracker: ROADMAP.md — synced with internal North Star v5.0.
Live board: GitHub Projects — Reactive Agents Roadmap.
Getting Help
- Discord -- Join the community for questions, discussions, and support
- GitHub Issues -- Report bugs or request features
- GitHub Discussions -- Ask questions and share ideas
- Security -- File privately via GitHub Security Advisory
Contributors
License
MIT